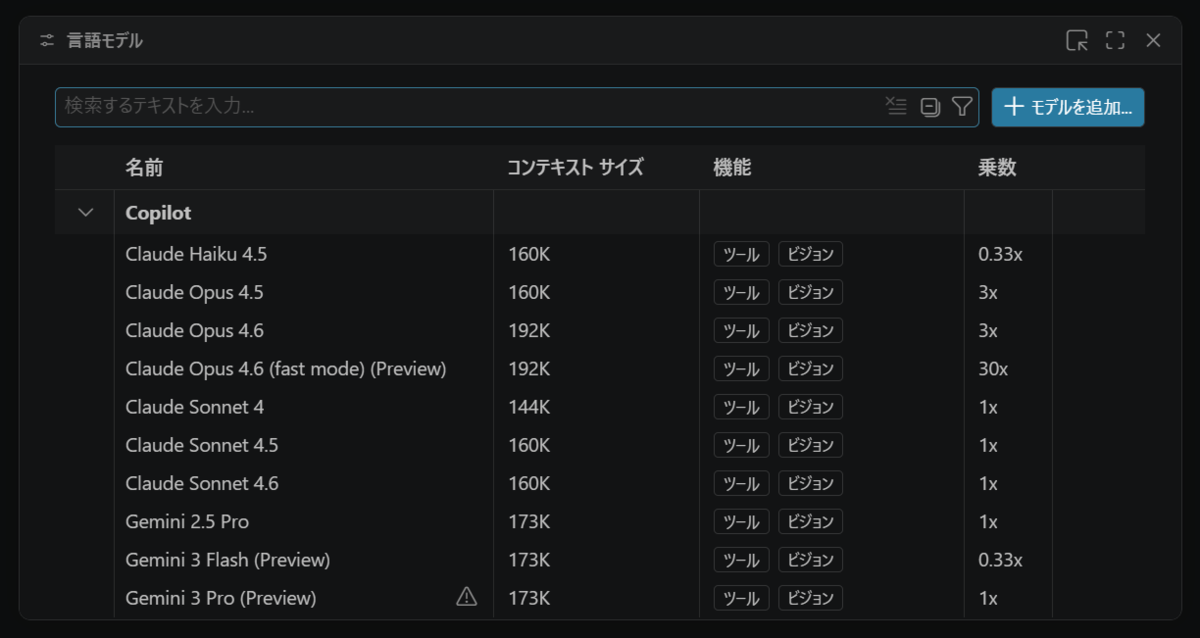
Phi3, Phi3.5, Phi4 関連
C# を使ってローカル PC の CPU か NPU かでお手軽にエッジ AI を始める方法
記事はこちらです。
hiro128.hatenablog.jp
C# を使って CPU で Edge AI を試してみよう(1)Phi モデルの概要
記事はこちらです。
hiro128.hatenablog.jp
C# を使って CPU で Edge AI を試してみよう(2)簡単なアプリを作成してみる
記事はこちらです。
hiro128.hatenablog.jp
C# を使って CPU で Edge AI を試してみよう(3)日本語で精度を高めるために、英語に翻訳してプロンプトを投げる
記事はこちらです。
hiro128.hatenablog.jp
C# を使って CPU で Edge AI を試してみよう(4)日本語の精度を高めるために、さらに RAG を導入してみる
記事はこちらです。
hiro128.hatenablog.jp
Phi モデルをローカルで検証できるサンプルアプリ
記事はこちらです。
hiro128.hatenablog.jp
Phi Silica 関連
待ちに待った Phi Silica がようやくやってきたので Text Completion を試してみた
記事はこちらです。
hiro128.hatenablog.jp
Phi Silica をコンソールアプリで動かしたらエラー発生、そして解決
記事はこちらです。
hiro128.hatenablog.jp
Phi Silica (Language Model)で日本語の実用性があるか試してみた。
記事はこちらです。
hiro128.hatenablog.jp
Phi Silica の Language Model を検証できるコンソールアプリ
記事はこちらです。
hiro128.hatenablog.jp