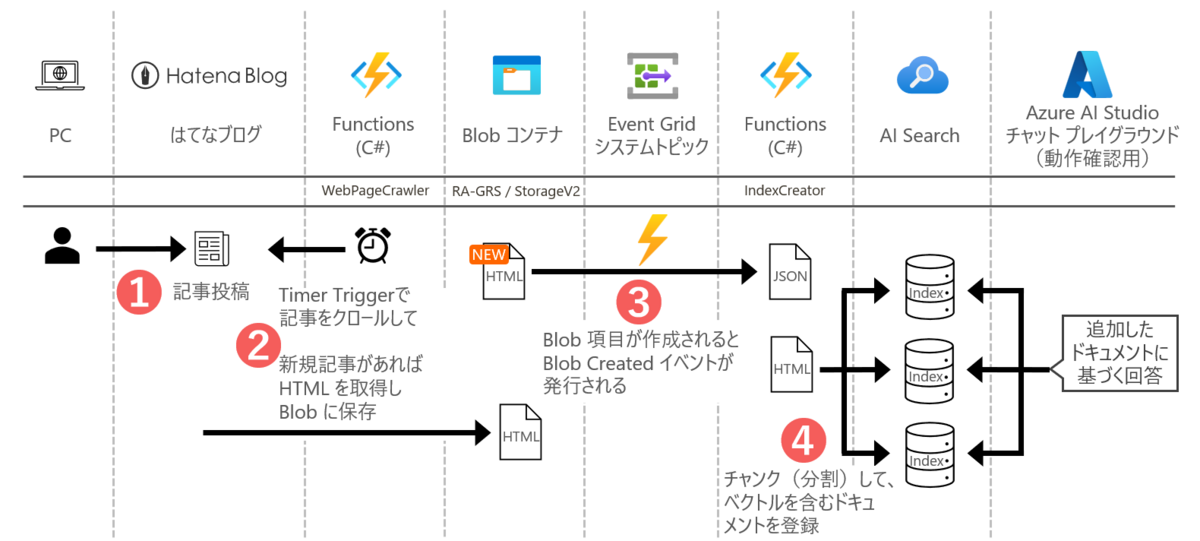
留意点②:Blob コンテナ上でのソースデータの更新日時の管理
このサンプルではストレージアカウントの SKU は以下の通りとなっています。

Blob 側の最終変更日は、コンテナにファイルがアップロードされた日時なので、
コンテナの項目のメタデータにソース記事の url とはてなブログの更新日時を記録しておきます。

Blob メタデータへ url と 最終更新日時を付加したうえで、Blob 上の既存項目から更新があればアップロードする
上述のとおり正しくインデックスのドキュメントを更新するためには、はてなブログでの更新日時が必要なため、Blob にアップロードする際に、はてなブログの当該記事の url と 最終更新日時をメタデータとして付与します。
作成したソースコードの詳細は以下を参照ください。
github.com
Blob 項目をアップロードするコードは以下の通りです。
async ValueTask UploadOrUpdateAzureBlobItem(HatenaBlogEntry entry, BlobClient blobClient) { var htmlStream = await httpClient.GetStreamAsync(entry.Url); var options = new BlobUploadOptions { HttpHeaders = new BlobHttpHeaders { ContentType = "text/html", }, Metadata = new Dictionary<string, string> { { "url", entry.Url }, { "lastUpdated", entry.LastUpdated.ToString()} } }; await blobClient.UploadAsync(htmlStream, options); }
はてなブログの記事を Blob にアップロードする際に新規記事は無条件にアップロードし、既存記事については Blob のメタデータに記録したアーカイブ済の Blob 項目の更新日時を確認し、変更があるもののみ再アップロードする必要があります。
よって、既存の Blob 項目の存在確認を実施し、日付を見てアップロードすべきもののみアップロードする制御を入れています。
また、関数アプリのホスティングプランは「従量課金」にしているので、失敗しないように uploadLimit で1回あたりの処理数を制限しています。
これらの処理については以下を参照ください。
// はてなブログの記事をAzure Blob Storageにアップロードする // (多すぎるとインデックス作成が失敗するので uploadLimit の設定値まで) async ValueTask UpdateAzureBlobContainerItems(List<HatenaBlogEntry> entries) { var currentUploadCount = 0; foreach (var (entry, index) in entries.Select((entry, index) => (entry, index))) { if (currentUploadCount >= uploadLimit) { logger.LogInformation($"Upload limit reached. {uploadLimit} articles uploaded."); break; } var blobName = entry.Url.Replace($"https://{hatenaID}.hatenablog.jp/entry/", "").Replace("/", "-") + ".html"; var blobClient = blobContainerClient.GetBlobClient(blobName); bool exists = await blobClient.ExistsAsync(); if (!exists) { logger.LogInformation($"Upload : {(index + 1).ToString("000000")}/{entries.Count.ToString("000000")} {entry.Url}"); await UploadOrUpdateAzureBlobItem(entry, blobClient); currentUploadCount++; } else { var response = await blobClient.DownloadAsync(); if (!string.IsNullOrEmpty(response.Value.Details.Metadata["lastUpdated"])) { var azureBlogLastUpdated = DateTimeOffset.Parse(response.Value.Details.Metadata["lastUpdated"]); // 面倒なのでタイムスタンプが一致しているときのみスキップ // つまり、はてな側の更新日が古くても上書きする // 理由:齟齬があるのは間違いなく、はてな側を正とすべきなのは何ら変わらないから if (entry.LastUpdated == azureBlogLastUpdated) { logger.LogInformation($"Skip : {(index + 1).ToString("000000")}/{entries.Count.ToString("000000")} {entry.Url}"); continue; } } logger.LogInformation($"Upload : {(index + 1).ToString("000000")}/{entries.Count.ToString("000000")} {entry.Url}"); await UploadOrUpdateAzureBlobItem(entry, blobClient); currentUploadCount++; } } }